
Inception Network
Original Source: https://www.coursera.org/specializations/deep-learning
1x1 Convolution - Network in Network
https://arxiv.org/abs/1312.4400
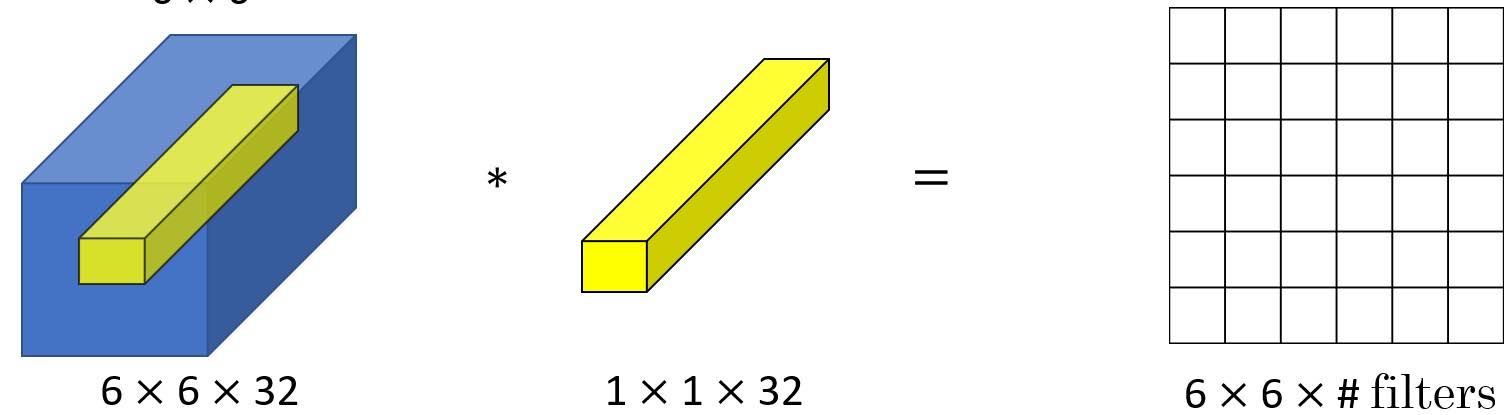
We use 1x1 convolution (or network in network) when we want to change the number of channels while maintaining height and width.
Also it can be used when we want to add non-linearity while keeping dimensions intact.
What is Inception?
https://arxiv.org/abs/1409.4842
Let’s say you are building a layer of a neural network and you don’t want to have to decide whether to use a 1 by 1, or 3 by 3, or 5 by 5, or pooling layer. Key concept of the ‘inception’ module is that it does that all and concatenate the results.
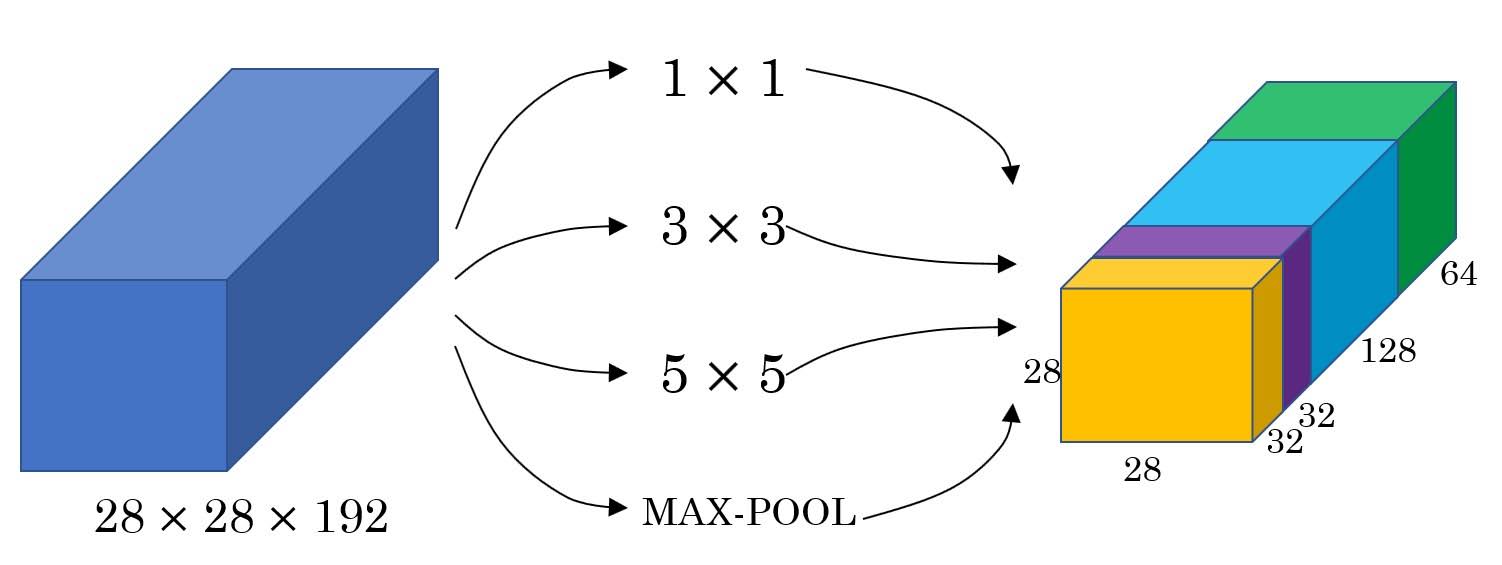
Note that you have to use same paddings to maintain the height and width so that outputs can be concatenated.
Computational Cost
But with so many calculations involved, we run to the problem of computational cost. For example, when we do 32 5x5 same convolutions to a volume of 28x28x192, we need about 120M(28x28x32x5x5x192) multiplications.
We can reduce this cost by about 1/10 using 1 by 1 convolution.
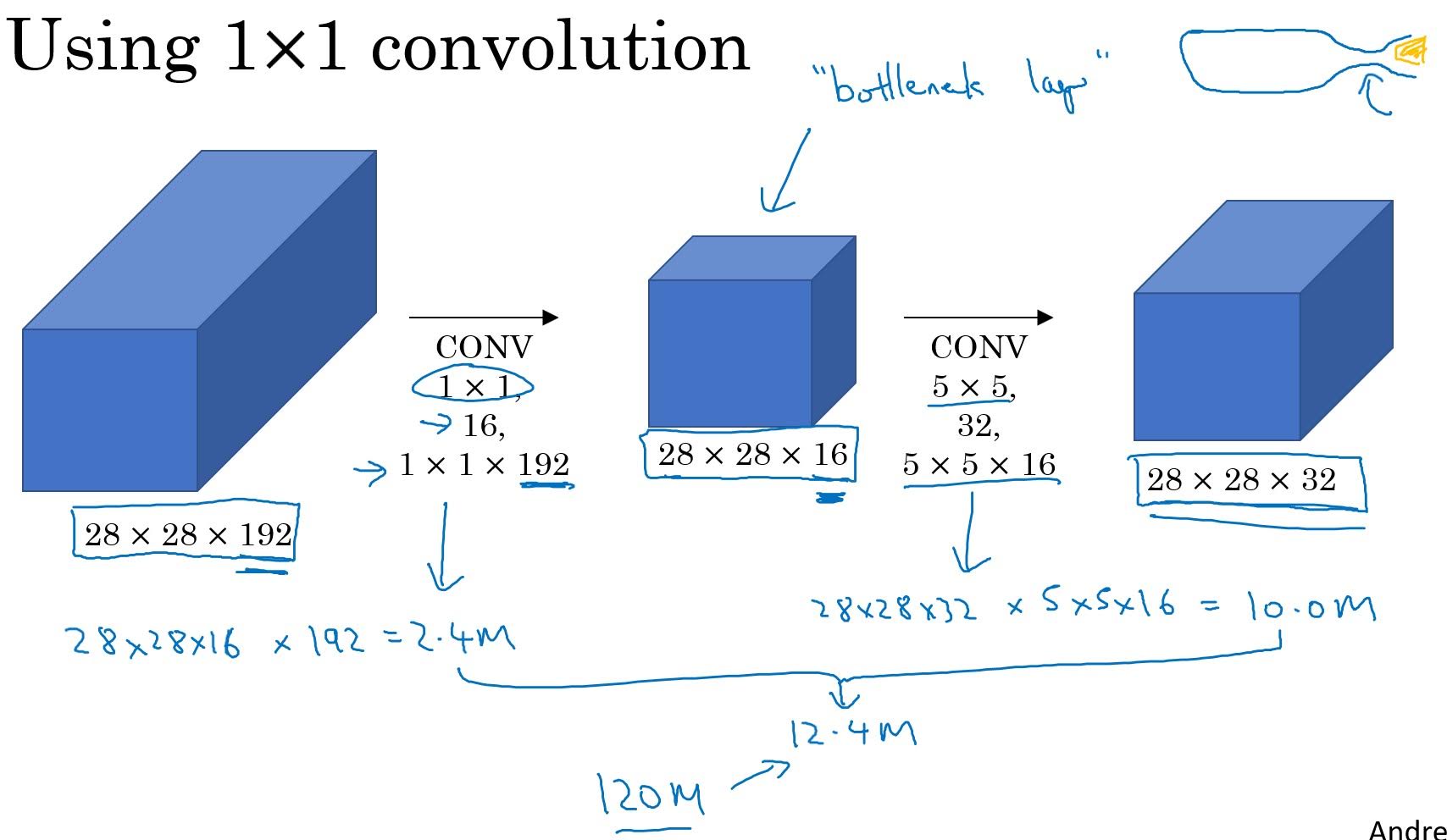
We now only need 2.4M(28x28x16x1x1x192)+10.0M(28x28x32x5x5x16)=12.4M multiplications. The output of this 1x1 convolution is called ‘bottleneck layer’.
So long as you implement this bottleneck layer within reason, it doesn’t seem to hurt the performance.
Inception Module
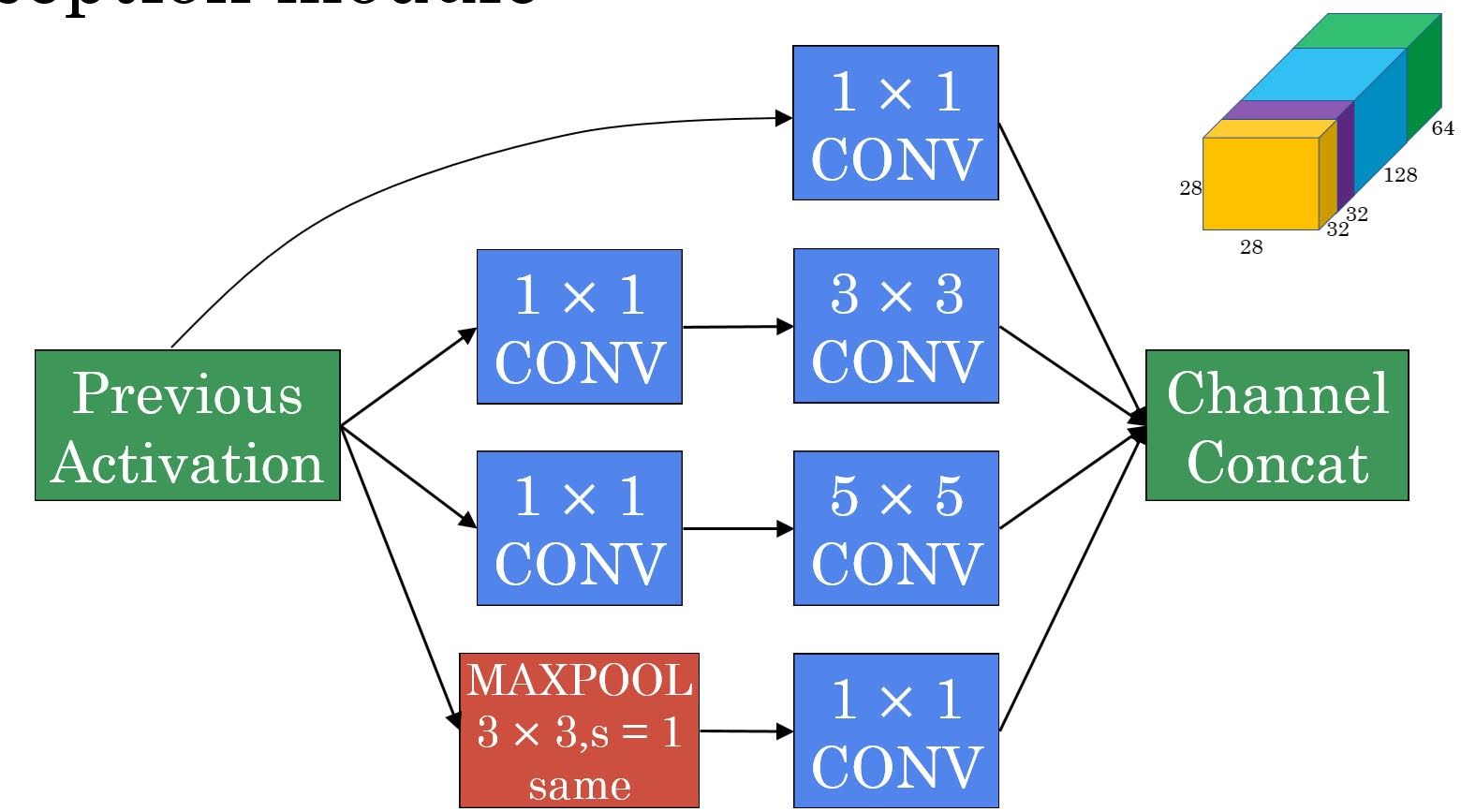
Note that we use 1x1 convolution after pooling.
Inception Network
We stack inception modules to construct inception network.
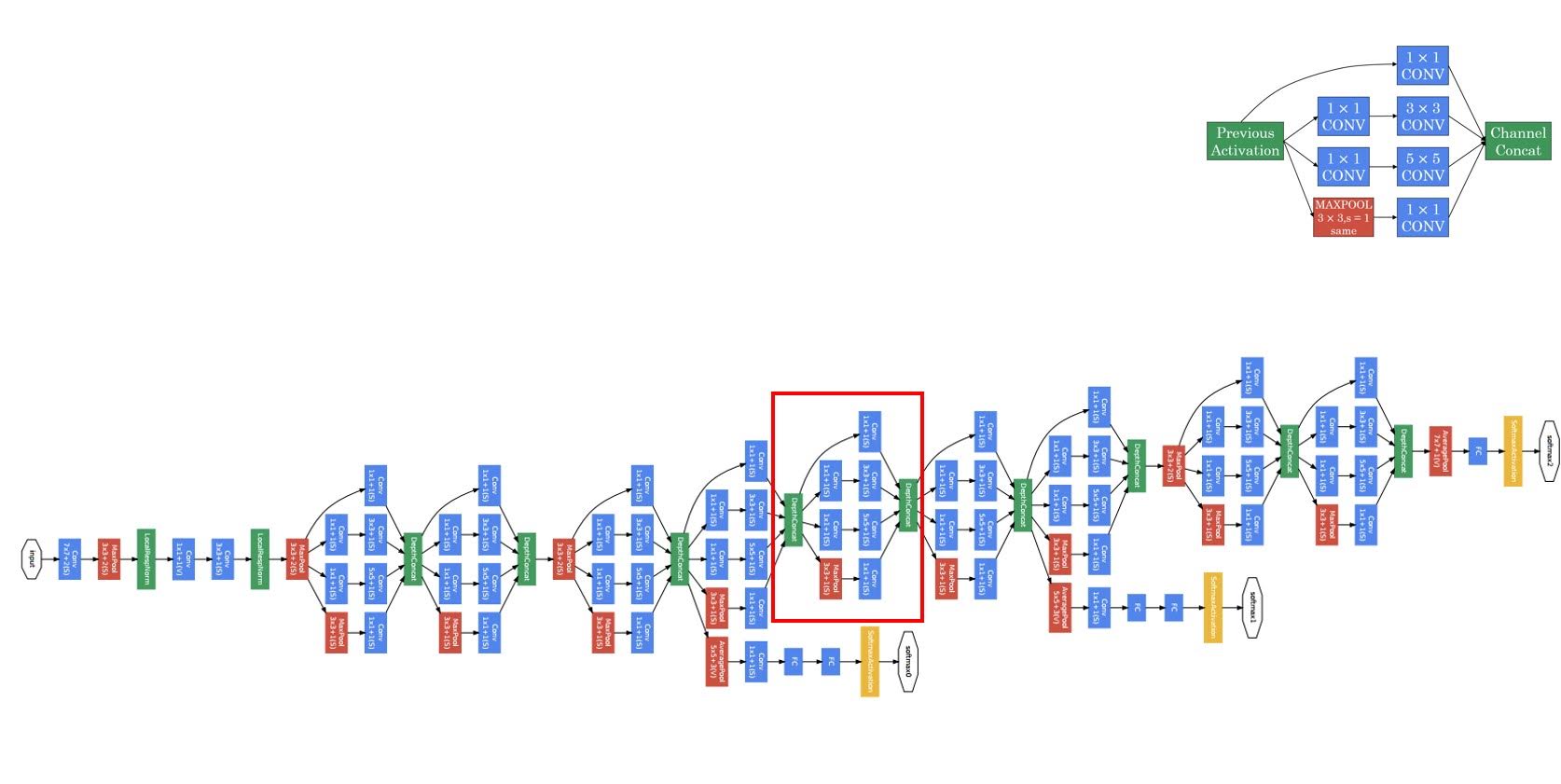
This particular Inception network was developed by authors at Google, who called it GoogleNet.
There are three branches that make prediction; one at the tail and two that comes out of hidden layers. We select the best prediction from these multiple predictions. We do this because moderately deep network may perform better than too deep network.


Leave a Comment