
Practical Advices for Using ConvNets
Original Source: https://www.coursera.org/specializations/deep-learning
1. Open Source Code
- use architectures of networks published in the literature
- use open source implementations if possible
- use pretrained models and fine-tune on your dataset
2. Transfer Learning
First, copy the network architecture of the related pre-trained network and initialize weights with the pre-trained weights.
- If you have small amount of data, freeze layers other than output layer of original network, then only train the output layer with your data.
- If you have moderate amount of data, freeze layers to about the middle of the layer, then train latter layers with your data.
- If you have plenty data, train the whole layer with your data.
3. Data Augmentation
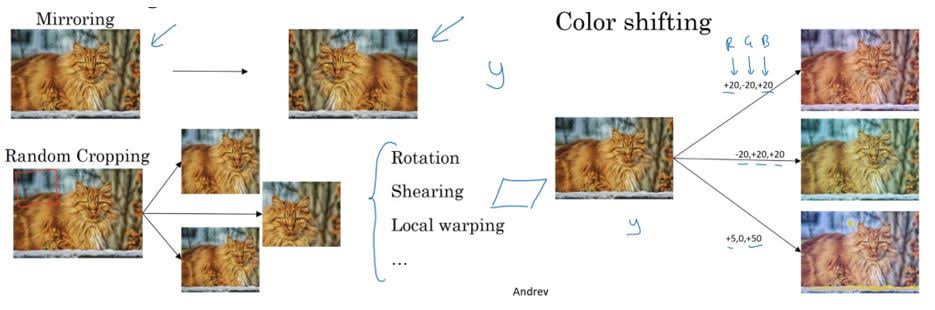
You can augmentate your training images by mirroring, cropping, color shifting and etc.
4. Hand-Engineering
If you don’t have enough data, you will need more hand-engineering. It means that you need to hand-engineer network architecture, features and other components for that specific problem.
For example, in object detection task, cost for getting labeled data is relatively high. So people have devised complex network architectures for object detection specifically.
Tips for doing well on benchmark/competition
I’ll introduce techniques that can improve the test score but have expensive computational cost. Theses techniques is not recommended at production.
1. Ensembling
Train several networks independently and average their outputs.
2. Multi-Crop
Run classifier on multiple versions of test images and average results.
For example, you can ‘10-crop’ your test image, pass them to your model, average their outputs and use that average to finally classify the image.
10-crop is cropping center, top-left, top-right, bottom-left, bottom-right of original image and mirrored image.



Leave a Comment