
Speech Recognition and Trigger Word Detection
Original Source: https://www.coursera.org/specializations/deep-learning
Preprocessing Audio Data
Common pre-processing step for audio data is to run raw audio clip and generate a spectrogram, like our ears do. Spectrogram is a 2d data where x-axis is time and y-axis is frequency, and each value is amount of energy at that time with that frequency.
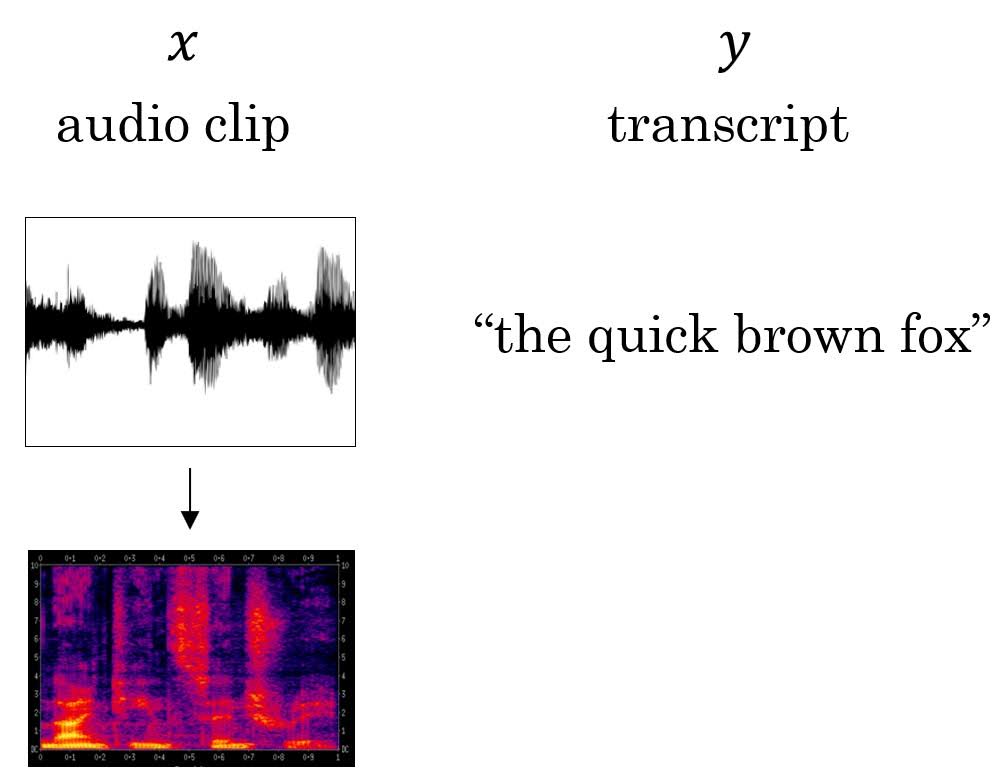
Speech Recognition
1. Attention Model
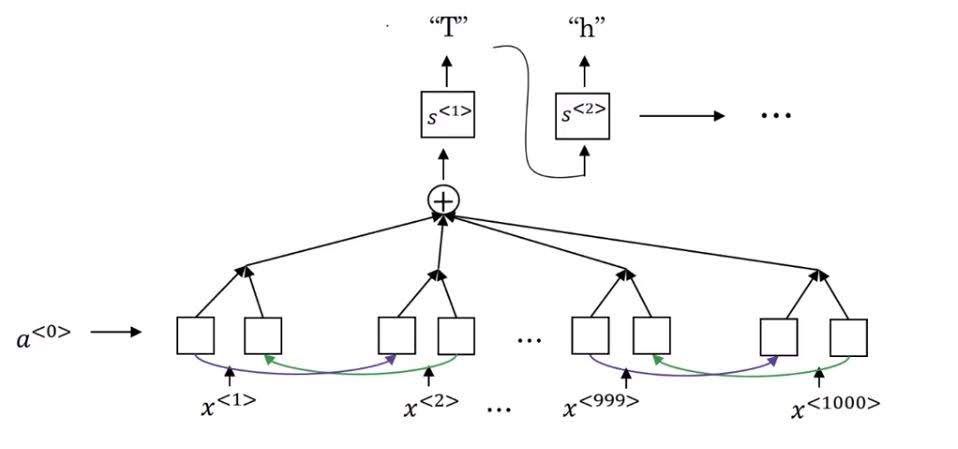
2. CTC(Connectionist Temporal Classification) Cost Model
CTC cost model allows you to use many-to-many RNN where input sequence length and output sequence length is equal, by allowing special character ‘blank’ and reapeated characters in the output sequence.
We collapse repeated characters not separated by ‘blank’ to get final output.
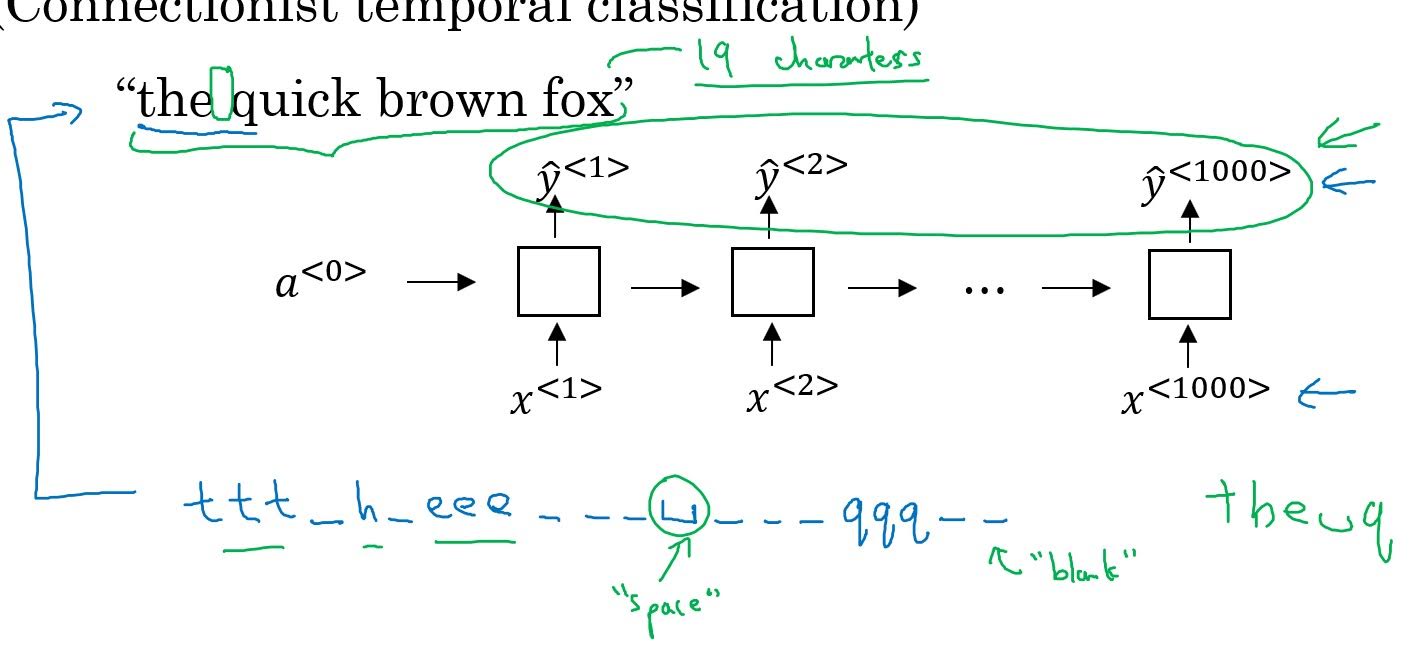
For example, say we have 1000 length input sequence, and the label is ‘the quick brown fox’, which only has 19 characters. To make this match length of the input sequence, we allow the model to output something like ‘ttt(b)h(b)eee(b)(b)(b)(s)(b)(b)(b)qqq(b)(b)(b)…’, where (b) is ‘blank’ and (s) is space. When computing cost, we transform that output into ‘the q…’.
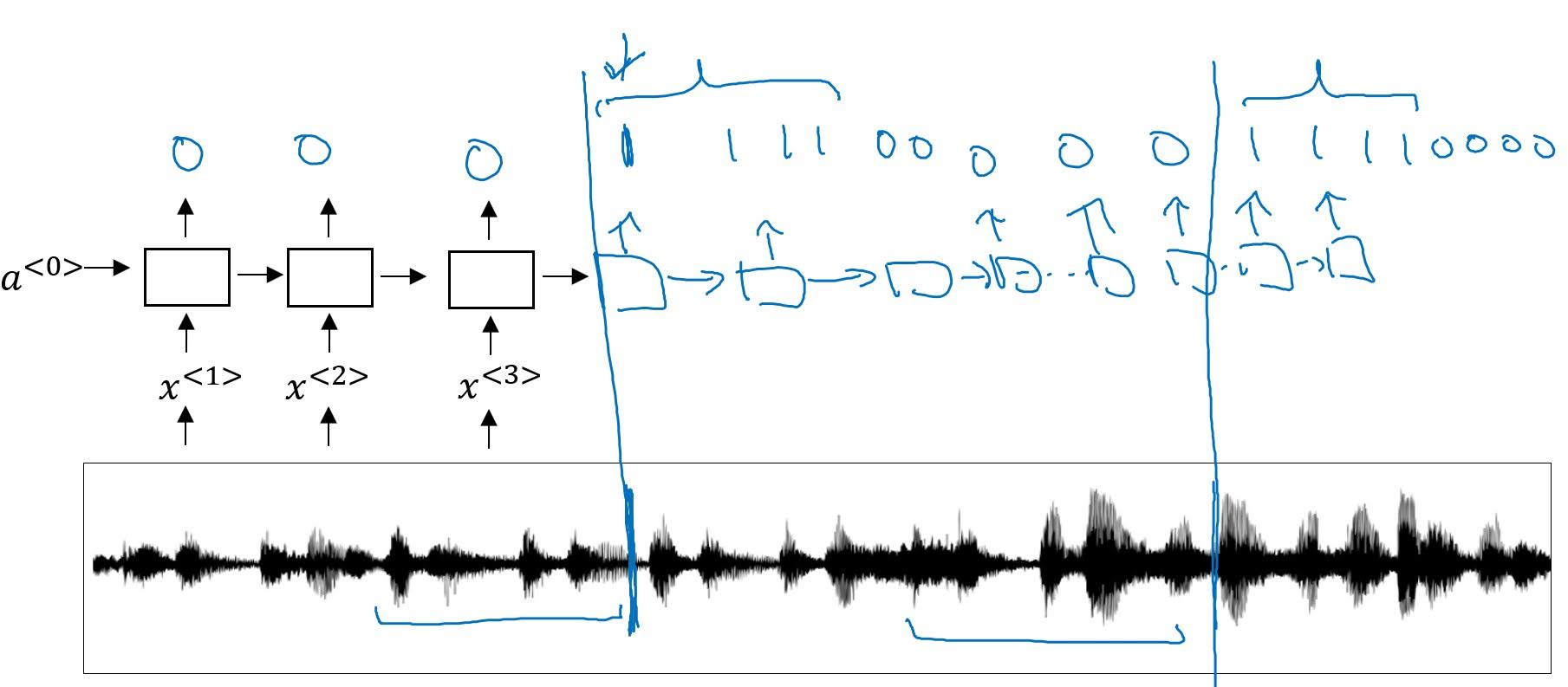
Trigger Word Detection
You give label of 0s to all of the outputs of RNN, except the places where someone has finished spoken trigger word. Giving only one 1 after trigger word will make an imbalanced training set, so in practice we give several 1s after trigger word to make your model train better.


Leave a Comment