
Data Mismatch of Training Set and Real World Examples
Original Source: https://www.coursera.org/specializations/deep-learning
Like always, say we want to develop an app that classifies cat images out of images that users upload.
It would be best if we have plenty of app images to train on. But say we only have 15000 app-uploaded images, so we gathered 205000 images from web.
Now, how should we divide them into train/dev/test sets?
It is important to have dev and test set come out of similar distribution with real world distribution. Train set need not have same distribution as real world examples since it is development set that we actually make decisions on selecting models.
We can divide our data like follows;
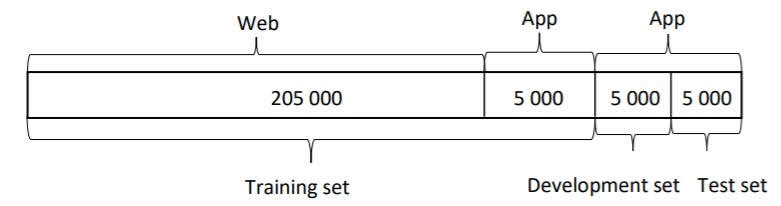
Training set having different distribution than dev/test set is called ‘Data Mismatch’.
With the prescence of data mismatch, we should use new way to measure variance. We divide original training set into new training set and training-development set. We train on the new training set, and validate on training-development set and development set. Then we measure variance based on errors of these two sets. We measure data mismatch based on difference between errors of development-training set and development set.

If you think error from data mismatch is significant, you should reduce data mismatch. We can do that by artificially synthesizing web images so that it look like app images or gathering more app images.


Leave a Comment