
End-to-End Deep Learning
Original Source: https://www.coursera.org/specializations/deep-learning
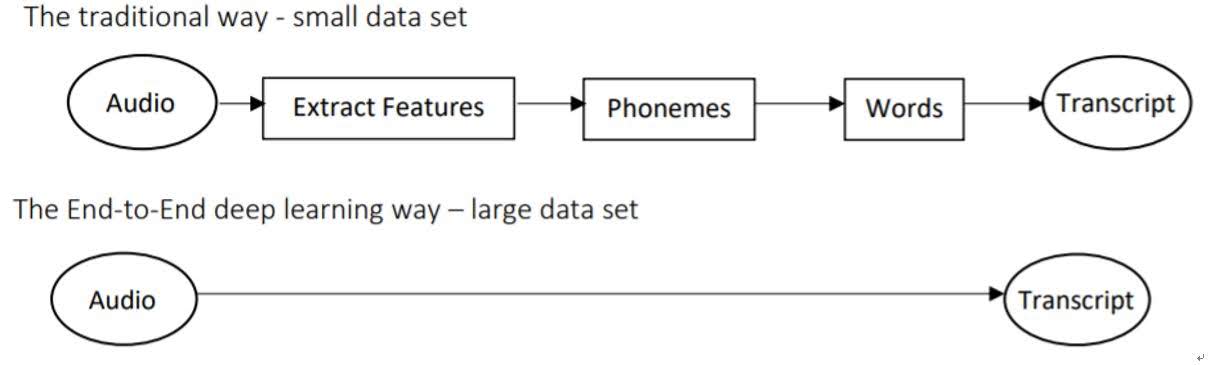
When there are not enough data, we might consider dividing one task into many tasks and training model for each of them. For example, say we want to make a model that outputs transcript of an input audio. We divide the task into four steps. Extracting features from audio, finding phonemes from features, constructing words from phonemes, then make a full transcript out of words.
However, if we have enough data, we can just train one model which outputs transcript with input audio. It might find out better ways to make transcript than the above four steps that we manually constructed. This is called ‘end-to-end deep learning’.
I’ll give one more example. Say we want to recognize face from an image. With traditional method, we first find the location of the face, than recognize it. But we end-to-end deep learning, we just train a model that recognizes a face that might show up anywhere in the image.
Pros and Cons of End-to-End Deep Learning
Pros
- Let the data speak rather than being forced to reflect human preconceptions.
- Less hand-designing of components needed
Cons
- Needs large amount of labeled data
- Excludes potentially useful hand-designed component


Leave a Comment