
“UNET++: A Nested U-Net Architecture for Medical Image Segmentation” Summarized
https://arxiv.org/abs/1807.10165 (2018-07-18)
I would recommend reading https://harangdev.github.io/papers/4/ (UNet Summarized) before reading this post.
1. Overall Architecture

UNet++ resembles UNet(https://arxiv.org/abs/1505.04597) but is different in 3 ways, as depicted in the above picture with color.
- Green: It has convolution layers on skip pathways, which bridges the semantic gap between encoder and decoder feature maps.
- Blue: It has dense skip connections on skip pathways, which improves gradient flow.
- Red: It has deep supervision, which enables model pruning and improves or in the worse case achieves comparable performance to using only one loss layer.
Now let’s look at the detailed architecture; re-designed skip pathways and deep supervision.
2. Re-designed Skip Pathways
The authors wanted the encoder feature maps and the corresponding decoder feature maps to be semantically similar. Then, the optimizer would face an easier optimization problem. To achieve this goal, they re-designed skip pathways between the U-Net encoder and decoder.
In U-Net, the feature maps of the encoder are directly received in the decoder. However, in UNet++, they undergo a dense convolution block whose number of convolution layers depends on the pyramid level.
Let’s call a horizontal skip pathway a ‘dense block’. Dense block is composed of many convolution layers like the above figure describing architecture. In each dense block, each convolution layer is preceded by a concatenation layer that fuses the output from the previous convolution layer of the same dense block with the corresponding up-sampled output of the lower dense block.
The Unet++ architecture can be expressed like the following equation;
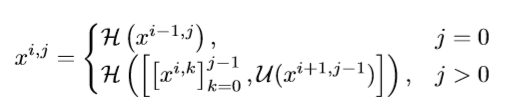
where
- $i$ indexes the down-sampling layer along the encoder
- $j$ indexes the convolution layer of the dense block
- $H()$ is a convolution operation followed by an activation function
- $U()$ denotes an up-sampling layer
- $[\;]$ denotes the concatenation layer
3. Deep Supervision
Deep supervision method is adding loss terms in the intermediate layers in deep network to enforce supervision for those intermediate layers. (https://arxiv.org/pdf/1409.5185)
The authors applied deep supervision to UNet++, enabling the model to operate in two modes;
- Accurate mode: the outputs from all segmentation branches are averaged
- Fast mode: the final segmentation map is selected from only one of the segmentation branches
Owing to the nested skip pathways, UNet++ generates full resolution feature maps at multiple semantic levels.
For loss function, a combination of binary cross-entropy and dice coefficient is used;
\[L(Y, \hat{Y}) = -\frac{1}{N}\sum^N_{b=1}(\frac{1}{2}Y_b\log{\hat{Y_b}}+\frac{2Y_b\hat{Y_b}}{Y_b+\hat{Y_b}})\]4. Experiments
The authors used 4 medical imaging datasets for model evaluation, covering lesions/organs from different medical imaging modalities.
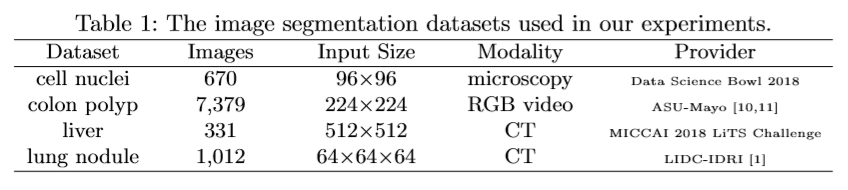
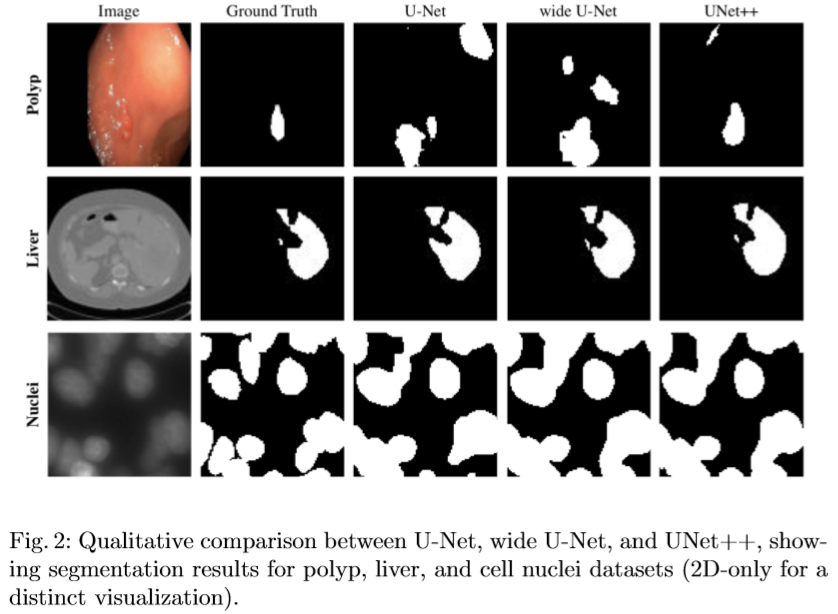
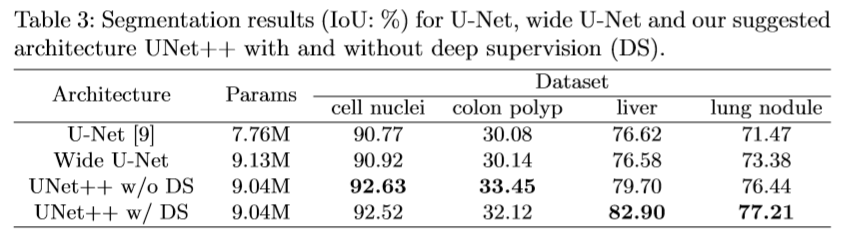
The results are described in the below figures.


Leave a Comment